jekyll实现文章搜索功能
在jekyll中可以使用simple-jeckyll-search插件实现文章搜索功能,可以实现大部分需求。我在使用simple-jeckyll-search过程中遇到了一些问题:
- 一个是想要将匹配的所有条目都显示出来,包括一篇文章中的多处匹配,并显示匹配位置的上下文;
- 另一个是
simple-jeckyll-search似乎并没有过滤掉文章中的某些html标签,导致能够搜索到一些html标签,这并不是我想要的。 上述两个问题能够解决,但是需要另外写的代码比较多,特别是第一个问题如果需要显示匹配位置的上下文基本需要再写一遍搜索。所以最后我打算自己写一个搜索组件。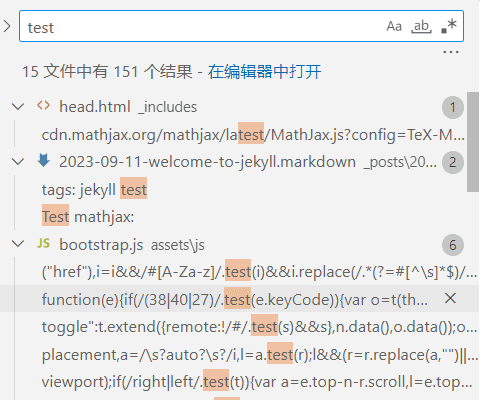
1. 整体思路
搜索时从rss文件中获取所有文章的标题、内容等信息,然后根据搜索关键词匹配文章标题和内容,将匹配的文章显示出来。参考了https://knightyun.github.io/2019/03/04/articles-search这篇文章。
2. 设计目标
能够实现搜索文章标题和内容,显示匹配的条目,不仅是文章的标题,还要把每一条匹配的内容前后的一些内容显示出来,以便用户更好的了解匹配的内容,并能点击跳转到对应的文章(跳转到文章中匹配的位置这个功能暂时先不做)。做成类似于vscode的全局搜索功能。
3. 实现过程
3.1 获取rss文件
rss文件是jekyll生成的一个xml文件,里面包含了所有文章的标题、内容等信息,可以通过http请求获取rss文件,然后解析rss文件。这里使用XMLHttpRequest来获取rss文件。
function makeHttpRequest(method, url, data) {
return new Promise(function (resolve, reject) {
var xhr = new XMLHttpRequest() || new ActiveXObject("Microsoft.XMLHTTP");
xhr.open(method, url, true);
xhr.onload = function () {
if (xhr.readyState == 4 && xhr.status == 200) {
resolve(xhr);
} else {
reject(xhr.statusText);
}
};
xhr.onerror = function () {
reject("网络错误");
};
if (data) {
xhr.setRequestHeader("Content-Type", "application/json");
xhr.send(JSON.stringify(data));
} else {
xhr.send();
}
});
}
makeHttpRequest("GET", "/feed.xml").then(function (xhr) {
console.log(xhr.responseText);
}).catch(function (err) {
console.error(err);
});
3.2 解析rss文件
rss的文件结构如下图所示:
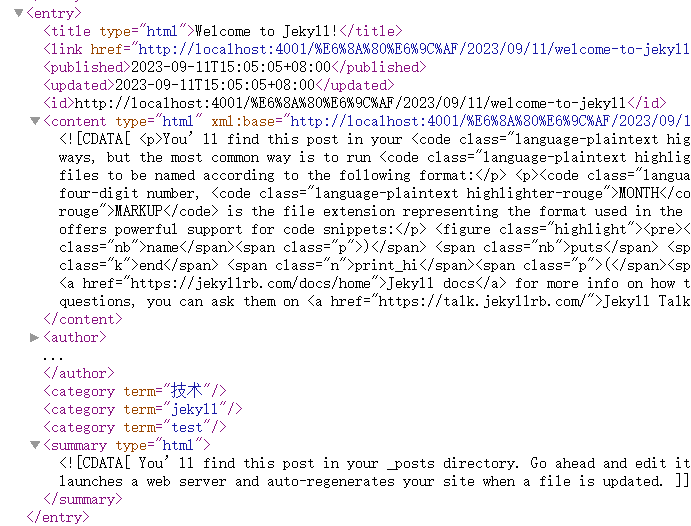 解析rss代码如下:
解析rss代码如下:
function getXmlData() {
articleData = [];
return new Promise(function (resolve, reject) {
makeHttpRequest("get", "/feed.xml")
.then(function (res) {
const xml = res.responseXML;
const items = xml.getElementsByTagName("entry");
for (const item of items) {
const title = item.getElementsByTagName("title")[0].childNodes[0].nodeValue;
const link = item.getElementsByTagName("link")[0].getAttribute("href");
let content = item.getElementsByTagName("content")[0].childNodes[0].nodeValue.replace(/<.*?>/g, "");
articleData.push({ title, link, content });
}
resolve(articleData);
}).catch(function (err) {
reject(err);
});
});
}
3.3 搜索匹配并显示
搜索时每篇文章用正则匹配查找:
const regExp = new RegExp(searchContent, "gi");
for (const item of articleData) {
if (item.title.match(regExp) || (!onlySearchTitle && item.content.match(regExp))) {
searchResults.push(item);
}
}
显示时,匹配的内容前后的一些内容也显示出来,给匹配文本添加上span标签用于高亮,最后将搜索到的这些匹配条目渲染到页面上。
function getMatchedPositions(keyword, content) {
const previewList = [];
let regex = new RegExp(keyword, "gi");
let match;
while ((match = regex.exec(content)) !== null) {
let startIndex = Math.max(0, match.index - 30);
let endIndex = Math.min(content.length, match.index + keyword.length + 40);
let preStr = content.substring(startIndex, match.index);
let suffixStr = content.substring(match.index + keyword.length, endIndex);
let matchStr = content.substring(match.index, match.index + keyword.length);
let preview = preStr + "<span class='highlight'>" + matchStr + "</span>" + suffixStr;
previewList.push(preview);
}
return previewList;
}
渲染时只需把上面得到的previewList添加到搜索结果容器的innerHTML中即可。
4. 效果展示

以上就是自己写的搜索组件的核心逻辑,完整代码请前往https://github.com/lxmghct/lxmghct.github.io/blob/master/assets/js/search.js
5. 实现优化
5.1 搜索数据来源优化
上面的搜索组件是从rss文件中获取数据,当前项目使用的是jekyll-feed插件生成rss文件,在config.yml中配置如下:
plugins:
- jekyll-feed
feed:
posts_limit: 20
posts_limit默认不设置会生成10篇文章,使用默认设置只能搜索前10篇文章,可以设置成一个较大的值,但是这样会导致rss文件较大,加载时间较长。简单测试了一下80篇长度中等的文章差不多是在1MB左右,这个大小对于一个rss文件来说还是可以接受的。即使再大一点,也不会太大,所以可以适当增大posts_limit的值。
由于rss中含有较多html标签,实际在搜索时并不需要这些标签,所以可以进一步优化rss文件。这里我打算自己生成一个json文件,只包含文章的标题、内容、日期和链接,这样可以减小文件大小,提高搜索效率。生成json文件的代码如下:
require 'json'
require 'cgi' # 用于处理 HTML 实体的转义和恢复
Jekyll::Hooks.register :site, :post_write do |site|
def strip_html(content)
content.gsub(/<\/?[^>]*>/, "")
end
def restore_html_entities(content)
CGI.unescapeHTML(content)
end
start_time = Time.now
all_posts = site.posts.docs.sort_by { |post| -post.date.to_i }.map do |post|
{
title: post.data['title'],
url: post.url,
date: post.date,
content: restore_html_entities(strip_html(post.content))
}
end
File.open('_site/assets/posts.json', 'w') do |file|
file.write(JSON.pretty_generate(all_posts))
end
end
使用正则表达式去除文章的html标签,并恢复原文本中的html实体,最后生成json文件。这样生成的json文件大概是原来rss文件的1/3大小,搜索效率也有所提高。
5.2 减少搜索频率
目前每次input输入框中的内容变化时都会触发搜索,这样会导致搜索频率过高,可以使用延时搜索的方式,0.5秒内无输入才触发搜索。
var inputTimeout = null;
function startSearch() {
inputTimeout && clearTimeout(inputTimeout);
if (articleData.length === 0) {
getJsonData().then(() => {
getSearchResult();
renderSearchResult();
})
} else {
getSearchResult();
renderSearchResult();
}
}
searchInput.addEventListener("input", function () {
inputTimeout && clearTimeout(inputTimeout);
inputTimeout = setTimeout(() => {
startSearch();
}, 500);
});